



工厂质量检测AI Agent搭建过程















如何让大模型看懂产线缺陷并自主分析根因?本文提出一套完整技术路径:GPT-4/Claude 3+YOLOv8/Swin Transformer + RAG知识库 + MCP工具调用。涵盖视觉模型选型对比、向量数据库搭建、LangChain工作流编排,并附三阶段实施路线图与监控指标建议。一文读懂工业质检的“端到端”智能化升级方案。

具体应用:作为系统的“决策大脑”,负责自然语言推理与多模态信息融合。它不直接处理图像,而是处理文本、标签和数据,进行根因分析、报告生成和决策建议。
推荐选型:
GPT-4/GPT-4 Turbo (API版本):首选。因其强大的推理能力和稳定的API性能,适合处理工业场景下的复杂逻辑。
Claude 3 (Anthropic):备选。其在长上下文和指令遵循方面表现优异,适合处理冗长的质量文档和标准。
本地部署模型 (如 Llama 3 70B, Qwen2 72B-Instruct):当数据安全与合规性要求极高,且拥有足够GPU算力时选择。需进行大量领域微调。
具体应用:是上述大模型和视觉模型的基础底层架构。
在LLM中:采用Transformer Decoder(如GPT系列)或Encoder-Decoder(如T5)结构,通过自注意力机制理解文本序列,完成生成任务。
在视觉模型中:Vision Transformer (ViT) 及其变体(如Swin Transformer)作为行业视觉模型的一种选择。ViT将图像分割为图块(patches)并视为序列,通过Transformer编码器提取特征,在多种缺陷检测任务上表现出超越传统CNN的性能,尤其擅长捕捉全局依赖关系。
具体应用:充当系统的“眼睛”,负责对图像进行像素级的感知和理解。
推荐选型 (非Transformer类):
YOLOv8/v9 (You Only Look Once):用于实时目标检测,快速定位缺陷 bounding box。适合对速度要求极高的产线。
U-Net:用于语义分割,精准勾勒出缺陷的像素级轮廓。适用于需要精确计算缺陷面积(如涂层脱落、划痕深度)的场景。
推荐选型 (Transformer类):
Swin Transformer:作为 backbone 网络,结合诸如 U-PerNet 等分割头,构建强大的分割模型。在复杂缺陷检测上精度更高。
DETR (DEtection TRansformer):采用Transformer编码器-解码器架构进行端到端目标检测,无需Anchor和NMS后处理。
具体应用:为LLM提供外部知识源,确保其回答基于工厂最新、最准确的标准和案例,避免“幻觉”。
技术栈:
向量数据库:Chroma (轻量、易用)、Milvus/Zilliz (高性能、可扩展)、Pinecone (全托管云服务)。用于存储和管理质量文档的向量嵌入(Embeddings)。
嵌入模型 (Embedding Model):OpenAI的text-embedding-3、BGE (BAAI General Embedding) 系列或Voyager。负责将知识库文档和用户查询转换为向量。
流程:用户查询 → 嵌入模型向量化 → 在向量数据库中检索Top K相似文档 → 将文档作为上下文注入LLM Prompt。
具体应用:由AWS等公司提出,是一种开放协议,用于标准化AI应用与外部数据源、工具(如数据库、API)之间的连接。它允许开发者为LLM构建安全的“插件”(称为Tools和Resources)。
在本Agent中的作用:可以极大地简化和标准化Agent访问工厂内部系统(如MES, CMMS, 时序数据库)的过程。
开发人员可以为MES系统编写一个MCP Tool,名为 query_mes_production_parameters(batch_id)。
在Prompt中,可以直接指示LLM“调用 query_mes_production_parameters 工具获取批次XYZ的参数”,LLM通过MCP服务器即可获取到结构化数据,无需复杂的中间件开发。
具体应用:设计高效、可靠的Prompt,将LLM、视觉模型、RAG、工具调用组织成一个连贯的工作流。
具体技术:
Prompt模板化:使用像LangChain、LlamaIndex 或 Semantic Kernel 这样的框架来构建和管理复杂的Prompt链。
少样本学习 (Few-Shot Learning):在Prompt中提供几个正例和反例,指导LLM输出符合要求的格式和内容。
思维链 (Chain-of-Thought):引导LLM分步推理,例如:“首先,描述缺陷;其次,结合工艺参数分析可能原因;最后,给出建议。”

1、数据基础与核心检测模型开发

数据治理:搭建数据管道,收集和清洗历史图像数据。进行精细化的数据标注(缺陷类型、位置、等级),构建高质量数据集。
视觉模型PoC:
基于选定的模型(如YOLO或U-Net)在数据集上进行训练和验证。
迭代优化,达到可接受的准确率与召回率。
将模型部署为高性能API(如使用NVIDIA Triton推理服务器)。
2、知识管理与Agent框架搭建
RAG建设:收集所有质量相关文档,进行文本预处理(分割、清理),使用嵌入模型向量化后存入向量数据库。
工具集成 (MCP):为需要访问的内部系统(MES、CMMS)开发MCP Server或标准的API接口。
Context设计与集成:使用LangChain等框架,编写核心Prompt链,定义好视觉模型API、RAG、工具调用的输入输出格式和集成顺序。
3、全流程集成与迭代优化
Agent集成测试:模拟真实生产环境,输入图像,测试从缺陷识别到报告生成的端到端流程。重点评估LLM推理的准确性和建议的可操作性。
反馈闭环建立:设计机制,让现场质检员可以对AI Agent的输出进行反馈(如“建议正确”/“建议错误”),这些反馈数据用于持续微调视觉模型和优化RAG知识库及Prompt。
部署与监控:将整个AI Agent部署到生产环境(边缘服务器或云平台),并建立性能监控面板,跟踪指标如:缺陷检出率、误报率、平均处理时间、用户采纳率。
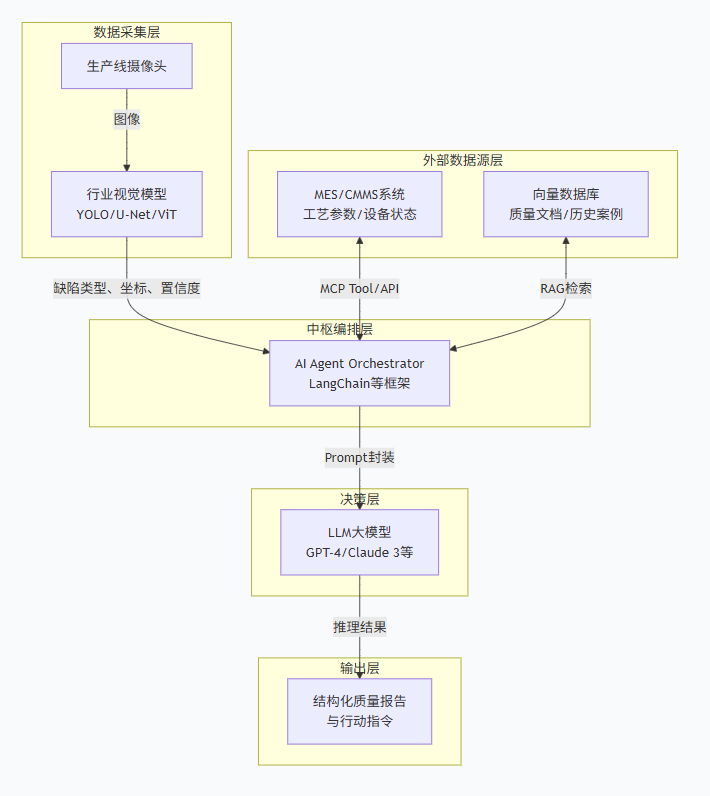
摄像头拍下产品 → 视觉模型找出缺陷 → Agent调取工艺参数和知识库 → 大模型分析根因 → 输出质检报告与处置指令。整个过程实现了从“看见”到“理解”再到“建议”的智能化闭环。
END
Leantek.cn
精易会

Leantek.cn
精易会
微信号丨精易会智造
官网丨leantek.cn
电话丨400-690-8780
邮箱丨 info@leantek.cn
地址丨江苏省苏州工业园区裕新路168号脉山龙大厦1号楼402室


